Linux IO模型简介和IO多路复用
-
这篇文章图是中文的 怎样理解阻塞非阻塞与同步异步的区别?
Linux IO模型
- 1.阻塞IO
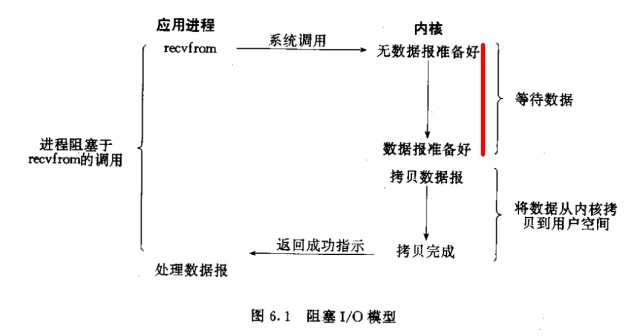
标红的这部分过程就是阻塞,直到阻塞结束recvfrom才能返回。
- 2.非阻塞IO
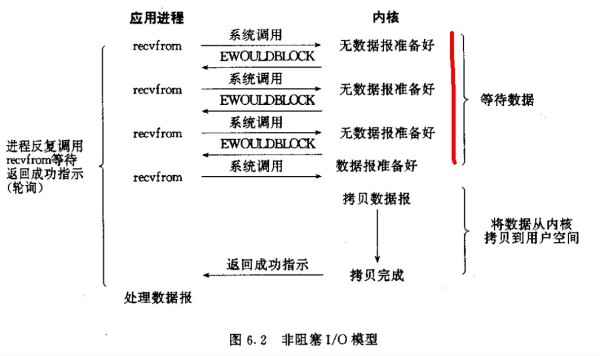
可以看出recvfrom总是立即返回。
- 3.IO多路复用
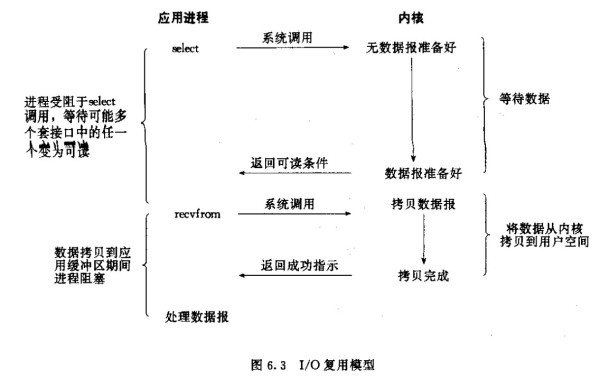
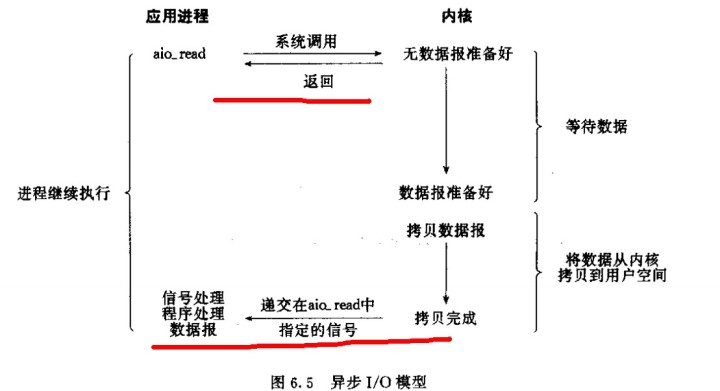
- 4.信号驱动异步I/O模型
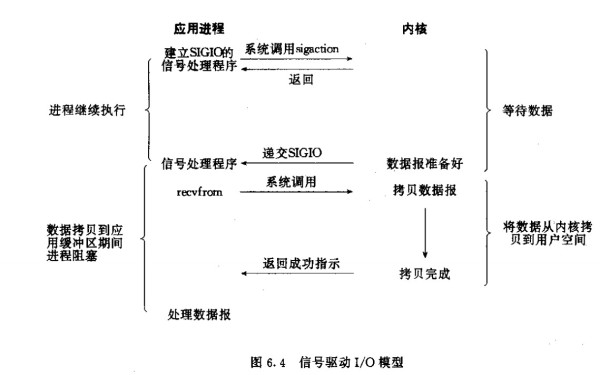
- 5.异步IO
- 五种模型对比

同步非阻塞方式相比同步阻塞方式:
优点是能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点是任务完成的响应延迟增大了,因为每过一段时间才去轮询一次,而任务可能在两次轮询之间的任意时间完成。
由于同步非阻塞方式需要不断轮询,而 “后台” 可能有多个任务在同时进行,人们就想到了循环查询多个任务的完成状态,只要有任何一个任务完成,就去处理它。这就是所谓的 “I/O 多路复用”。UNIX/Linux 下的 select、poll、epoll 就是干这个的(epoll 比 poll、select 效率高,做的事情是一样的)。Windows 下则有 WaitForMultipleObjects 和 IO Completion Ports API 与之对应(Windows API 的命名简直甩 POSIX API 几条街有木有!)
IO多路复用
目前支持I/O复用的系统调用有select、pselect、poll、epoll,下面几小结分别来学习一下select和epoll的使用。
Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP。
其实,epoll与select原理类似,只不过,epoll作出了一些重大改进,即:
- 1.支持一个进程打开大数目的socket描述符(FD)
select 最不能忍受的是一个进程所打开的FD是有一定限制的,由FD_SETSIZE设置,默认值是2048。对于那些需要支持的上万连接数目的IM服务器来说显然太少了。这时候你一是可以选择修改这个宏然后重新编译内核,不过资料也同时指出这样会带来网络效率的下降,二是可以选择多进程的解决方案(传统的 Apache方案),不过虽然linux上面创建进程的代价比较小,但仍旧是不可忽视的,加上进程间数据同步远比不上线程间同步的高效,所以也不是一种完美的方案。不过 epoll则没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子,在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
- 2.IO效率不随FD数目增加而线性下降
传统的select/poll另一个致命弱点就是当你拥有一个很大的socket集合,不过由于网络延时,任一时间只有部分的socket是"活跃"的,但是select/poll每次调用都会线性扫描全部的集合,导致效率呈现线性下降。但是epoll不存在这个问题,它只会对"活跃"的socket进行操作---这是因为在内核实现中epoll是根据每个fd上面的callback函数实现的。那么,只有"活跃"的socket才会主动的去调用 callback函数,其他idle状态socket则不会,在这点上,epoll实现了一个"伪"AIO,因为这时候推动力在os内核。在一些 benchmark中,如果所有的socket基本上都是活跃的---比如一个高速LAN环境,epoll并不比select/poll有什么效率,相反,如果过多使用epoll_ctl,效率相比还有稍微的下降。但是一旦使用idle connections模拟WAN环境,epoll的效率就远在select/poll之上了。
- 3.使用mmap加速内核与用户空间的消息传递。
这点实际上涉及到epoll的具体实现了。无论是select,poll还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的。
- 4.内核微调
这一点其实不算epoll的优点了,而是整个linux平台的优点。也许你可以怀疑linux平台,但是你无法回避linux平台赋予你微调内核的能力。比如,内核TCP/IP协议栈使用内存池管理sk_buff结构,那么可以在运行时期动态调整这个内存pool(skb_head_pool)的大小 --- 通过echo XXXX>/proc/sys/net/core/hot_list_length完成。再比如listen函数的第2个参数(TCP完成3次握手的数据包队列长度),也可以根据你平台内存大小动态调整。更甚至在一个数据包面数目巨大但同时每个数据包本身大小却很小的特殊系统上尝试最新的NAPI网卡驱动架构。